Probability and Statistics Seminar at Boston University

Probability and Statistics Seminar at Boston University
| Day: | Tuesdays (Sometimes Thursdays) | Click
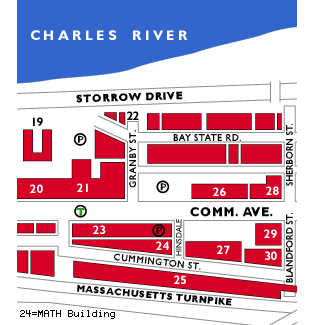
here for directions to the Boston University Department of
Mathematics and Statistics.
Campus text map, gif map , and a general area map. |
| Time: | 10am-noon (sometimes earlier) | |
| Place: | Room 135, Department of Mathematics and Statistics, 111 Cummington St., Boston University |
Go to the most recent scheduled talk.
This is a research oriented seminar, coordinated by Professor Murad Taqqu.
In the academic year 2006-2007, we will cover different topics, such as risk analysis, rare-event simulation and self-similar processes. There will be talks by invited speakers.
This seminar has now become a regular feature of Boston University and is also attended by mathematicians, scientists and postdoctoral fellows in the greater Boston area. Announcements will be done by email and through my Web Page:
2002-2003 "Extreme Values and Financial Risk." Click here to see the lisk of talks for that year.
2003-2004 (no seminar - sabbatical)
2006-2007(schedule updated weekly)
FALL SEMESTER 2006
This fall semester the talks will usually be on Tuesdays but sometimes on Thursdays.
- Tuesday, September 12, 2006
(10-noon)
Quantitative Models for Operational Risk
Johanna Neslehova (ETH, Zurich and Harvard University) Due to the new regulatory guidelines known as Basel II for banking and Solvency 2 for insurance, the financial industry is looking for qualitative approaches to and quantitative models for operational risk. This talk gives an overview of the Basel II requirements for quantitative modeling of operational risk and discusses several possible approaches. Special focus is laid on the advanced measurement approach and the calculation of the operational-risk capital charge. We also raise several issues concerning diversification effects and overall quantitative risk management consequences of extremely heavy-tailed data.
- Tuesday, September 19, 2006
(10-noon)
Self-similarity and computer network traffic: an introduction
Murad S. Taqqu (Boston University) Self-similarity refers to invariance in distribution under a suitable change of scale. The standard example is the Gaussian process known as fractional Brownian motion whose increments display long-range dependence. Ethernet local area network traffic appears to be approximately statistically self-similar. This discovery, made about twelve years ago, has had a profound impact on the field. This is the first of a series of talks on this subject and on self-similarity in general which will be one of our main topics this semester.
- Tuesday, September 26, 2006
(10-noon)
Fractional Brownian motion and long-range dependence
Murad S. Taqqu (Boston University) Long-range dependence in a stationary time series occurs when the covariances tend to zero like a power function and so slowly that their sums diverge. It is often observed in nature, for example in economics, telecommunications and hydrology. It is closely related to self-similarity. Self-similarity refers to invariance in distribution under a suitable change of scale. To understand the relationship between self-similarity and long-range dependence, suppose that the self-similar process has stationary increments. Then these increments form a stationary time series which can display long-range dependence. Conversely, start with a stationary time series (with long-range dependence). Then a central limit-type theorem will yield a self-similar process with stationary increments. The intensity of long-range dependence is related to the scaling exponent of the self-similar process. We shall provide here a tutorial on fractional Brownian motion, the Gaussian self-similar process with stationary increments, on its increment process known as fractional Gaussian noise, which displays long-range dependence. If there is time, we will also talk about a large class of long-range dependent stationary sequences called FARIMA, which are commonly used in modeling such physical phenomena.
- Tuesday, October 3, 2006
(10-noon)
Long-range dependence, fractional Gaussian noise and FARIMA models
Murad S. Taqqu (Boston University) Long-range dependence in a stationary time series occurs when the covariances tend to zero like a power function and so slowly that their sums diverge. The basic example of a long-range dependent time series is fractional Gaussian noise which is the increment of fractional Brownian motion and also a fixed point of the renormalization group. We will introduce fractional Gaussian noise as well, as well as the FARIMA sequences which are extension on the classical ARMA sequences but can also display long-range dependence.
- Tuesday, October 17, 2006
(10-noon)
Connections between self-similar stable mixed moving averages and flows
Murad S. Taqqu (Boston University) Self-similarity involves invariance of the probability distribution under scaling and it is characterized by a parameter H. Brownian motion, for example, is self-similar with H=1/2. Fractional Brownian motion is a stochastic process parameterized by H with three characteristics: it is Gaussian, is self-similar and has stationary increments. It is the unique process with these characteristics.
If the Gaussian distribution is replaced by an infinite variance symmetric alpha-stable distribution, then one does not have unicity anymore. There are in fact an infinite number of processes X that are symmetric alpha-stable, self-similar with stationary increments. We want to classify a subclass of them, the so-called "mixed moving average" ones by relating their representations to flows.
We obtain a decomposition of the process X, unique in distribution, into three independent components, which we characterize and associate with flows. The first component is associated with a dissipative flow. Examples include the limit of telecom process, the so-called ``random wavelet expansion'' and Takenaka processes. The second component is associated with a conservative flow. Particular cases include linear fractional stable motions.
This is joint work with Vladas Pipiras.
- Tuesday, October 31, 2006
(10-noon)
Stable stationary processes related to cyclic flows
Murad S. Taqqu (Boston University) Rosinski has shown that one can decompose a stationary stable process into three independent components:
(1) a mixed moving-average process
(2) a harmonizable process
(3') a component which is none of the above.
We show that one can identify a "cyclic" component in category (3'). One can therefore decompose a stationary stable process into independent four components. The components (1) and (2) listed above, and
(3) a cyclic (non-harmonizable) process
(4) a process which is none of the above.
Category (4) contains for example the stationary sub-Gaussian processes. The cyclic processes (3) are related to cyclic flows. These processes are not ergodic. We characterize them, provide examples and show how to identify them among general stationary stable processes. This is joint work with Vladas Pipiras.
- Tuesday, November 7, 2006
(10-noon)
Dependence structures of some infinite variance stochastic processes
Murad S. Taqqu (Boston University) Fractional Gaussian noise is a Gaussian process whose increments exhibit long-range dependence. There are many extensions of that process in the infinite variance stable case. Log-fractional stable noise (log-FSN) is a particularly interesting one. It is a stationary mean-zero stable process with infinite variance, parametrized by a number alpha between 1 and 2. The lower the value of alpha, the heavier the tail of the marginal distributions. The fact that alpha is less than 2 renders the variance infinite. Therefore dependence between past and future cannot be measured using the correlation. There are other dependence measures that one can use, for instance the "codifference" or the "covariation". Since log-FSN is a moving average and hence "mixing", these dependence measures converge to zero as the lags between past and future become very large. We show that the codifference decreases to zero like a power function as the lag goes to infinity. The value of the exponent, which depends on alpha, measures the speed of the decay. There is also a multiplicative constant of asymptoticity c which depends also on alpha and plays an important role. This constant c turns out to be positive for symmetric alpha-stable log-FSN, and the rate of decay of the codifference is such that one has long-range dependence. We also show that a second measure of dependence, the "covariation", converges to zero with the same intensity and that its constant of asymptoticity is positive as well. This is joint work with Joshua B. Levy.
- Tuesday, November 28, 2006
(10-noon)
Rotational and Other Representations of Stochastic Matrices I
Vidhu (Raj) S. Prasad (University of Massachusetts at Lowell) Since this is a talk in the probability seminar, no knowledge of ergodic theory is assumed. There will be many examples and the talks will be covered in a leisurely pace to maximize understanding. The results presented in this talk is joint work with S. Alpern (LSE).
Joel E. Cohen (1981) conjectured that any n x n stochastic matrix P = (p(i,j)) could be represented by some circle rotation R in the following sense: For some partition {S(i): i=1,...,n} of the circle into sets consisting of finite unions of arcs, the rotation R moves the partition according to the matrix P, in the following sense
(*) p(i,j}) = m [R(S(i)) \cap S(j)]/ m [S(i)]
where m denotes arc length (i.e., the relative proportion of S(i) moving into S(j) under R, is given by p(i,j)). In this talk we establish the Coding Theorem, that any mixing stochastic matrix P can be represented (in the sense of (*) but with S(i) merely measurable) by any aperiodic measure preserving bijection (automorphism) R of a Lesbesgue probability space.
In addition to the Coding Theorem, our approach considers two other theorems in ergodic theory concerning a fixed aperiodic measure preserving transformation R of a Lebesgue probability space (X, m) and shows that each of these three theorems is a simple corollary of any other. One these theorems (Conjugacy Theorem) asserts that the conjugates of any aperiodic transformation R is a dense class in the uniform topology on the space of automorphisms.
The other result is Alpern's generalization of the Rokhlin Lemma, the so-called Multiple Rokhlin Tower Theorem stating that the space can be partitioned into denumerably many R-columns, and the measures of the columns can be prescribed in advance. We give a simple proof of the Multiple Rokhlin Tower Theorem (joint with S. Eigen (Northeastern)), thereby establishing the Coding Theorem and the Conjugacy Theorem.
- Tuesday, December 5, 2006
(10-noon)
Rotational and Other Representations of Stochastic Matrices II
Vidhu (Raj) S. Prasad (University of Massachusetts at Lowell) Joel E. Cohen (1981) conjectured that any n x n stochastic matrix P = (p(i,j)) could be represented by some circle rotation R in the following sense: For some partition {P(i): i=1,...,n} of the circle the rotation R moves the partition according to the matrix P, in the following sense:
(*) p(i,j)= m (R(P(i)) \cap P(j))/ m(P(i))
where m denotes arc length (the relative proportion of P_i moved by R into P_j is given by p(i,j).
Our approach to Cohen's problem is to show how this conjecture is equivalent to two other problems in ergodic theory. We will then show how to prove one of these ergodic theory problems.
Since this is an expository talk in the probability seminar, no knowledge of ergodic theory is assumed. There will be many examples and the talks will be covered in a leisurely pace to maximize understanding. This represents joint work with S. Alpern (LSE). This continues the talk begun last week.
TRANSPARENCIES: for last week's talk and the upcoming talk can be downloaded (Thursday morning) from the speaker's homepage at http://faculty.uml.edu/vprasad/RotationTalkBU.pdf, or in the notes in a continuous form as http://faculty.uml.edu/vprasad/RotationTalkBU-article.pdf
- Tuesday, December 12, 2006
(10-noon)
Statistical Aspects of Chaos and Chaos Communication
Tony Lawrance (University of Warwick, Coventry, UK) This presentation will be introductions to both statistical aspects of chaos and chaos-based communication performance modelling. The first is more generic and presents the main aspects of chaos of interest to statisticians. By chaos here we just mean continuous-valued time series which are generated by simple nonlinear mathematical recursions, such as tent, modulo, logistic and Chebyshev maps. If you do not know the generating process, but just consider numerical realizations, they look "stochastic" and have well-defined statistical properties. There is an analogy with random number generators, and more practically with laser generated series. Interestingly, one can think of a chaotic sequence as the most extreme opposite of an independent sequence. The statistical properties of interest are marginal distribution and dependence, both linear and nonlinear, and a sum of squares quantity, and not the sensitivity and dimensionality of traditional chaos theory.
The second part introduces the area of chaos-based communications, a topic originating in radio- and laser- based communications research. Instead of the traditional sinusoidal radio waves, chaotic ones are used. Although still in the experimental stage, there are perceived qualities of security and in capacity from being "spread-spectrum", and also some serious practical questions of implementation and performance. This talk will outline one particular mathematical model for chaos communication, the binary "chaos shift keying" system, and study its performance in terms of bit error, that is when a 1 is decoded at the receiver as a 0 and vice-versa. Decoders are essentially statistical estimators which can be invented or derived by statistical principles, and it is their properties which are important. The speaker's work has involved developing exact theory of bit error performance, replacing inaccurate "engineering" approximations and giving more insight. One particular theoretical concern has been to identify a system with minimum bit error. It has been shown how this can be achieved by minimising a chaotic sum of squares and that it requires use of a particular chaotic map. There are a variety of other possible topics, such as alternative measures of performance, likelihood optimal decoders, jamming and multi-user systems. Four references to the speaker's work on this topic are:
EMAIL: A.J.Lawrance@warwick.ac.uk
REFERENCES:
1. Statistical aspects of chaotic maps with negative dependency in a communications setting, with N Balakrishna. J. R. Statistic. Soc. B (2001), 63, 843-853.
2. Exact calculation of bit error rates in communication systems with chaotic modulation, with G Ohama. IEEE Transactions on Circuits and Systems �I: Fundamental Theory and Applications, (2003), 50, 1391-1400.
3. Bit error probability and bit outage rate in chaos communication, with G.Ohama. Circuits, Systems and Signal Processing, (2005), 24, 5, 519-534.
4. Performance analysis and optimization of multi-user differential chaos-shift-keying communication systems, with J Yao. IEEE Transactions on Circuits and Systems �I: Regular Papers (2006), 53, 9, 2075-2091.
SPRING SEMESTER 2007
- Tuesday, January 23, 2007
Topics on Rare-Event Simulation I
Jose H. Blanchet (Harvard University) Estimation of "small" (i.e. rare-event) probabilities is of particular interest in a variety of applied probability contexts. For instance, in queueing applications, such small probabilities may correspond to long sojourn times. In insurance risk theory, it is of interest to study ruin probabilities which typically tend to be very small. Computations related to risk measures in finance involve tail probabilities that also relate to rare events. Counting complex combinatorial structures, such as contingency tables, which is of interest in Computer Science and Statistics can often be posed as a rare-event estimation problem.
Because closed-form evaluation of rare-event probabilities is in most cases very difficult, simulation provides a natural computational tool. However, direct Monte Carlo methods may take long to provide good (in relative terms) estimators. During these lectures, we shall discuss some popular techniques used in the context of rare-event simulation. In most cases, these techniques involve understanding the conditional dynamics of a stochastic system subject to extreme events. As a consequence, theoretical tools such as large deviations and extreme value theory are often very helpful in designing efficient rare-event simulation methodology. Our lectures will discuss basic ideas related to large deviations theory (both in light and heavy-tailed settings) and their applications in the design of algorithms that can be proved to be efficient in precise terms.
ABSTRACT OF THE FIRST LECTURE:
We will start with a series of motivating examples in several contexts, such as queueing, insurance risk and computational finance. Then, we shall introduce "importance sampling" which is a variance reduction technique that is widely used in rare-event simulation. The concept of efficiency and its connection to computational complexity will then be discussed. A formal introduction to basic large deviations ideas will be given in the context of Cramer's theorem for sums of iid rv's. We then will be ready to provide one of the most fundamental examples of efficient rare-event simulation algorithms for sums of iid rv's and analyze its complexity.
- Tuesday, January 30, 2007
Topics on Rare-Event Simulation II
Jose H. Blanchet (Harvard University) In the first lecture we discussed several examples in which rare-event simulation can be applied to estimate probabilities of interest. We also discussed various concepts of efficiency and basic ideas behind importance sampling.
During the second lecture we will start by characterizing the zero-variance change-of-measure as a conditional distribution. Then, we shall discuss large deviation techniques for sums of iid light-tailed random variables. We will then use large deviations to provide descriptions of conditional distributions, which correspond asymptotically to zero-variance importance samplers. These conditional limit theorems, then will suggest natural importance sampling algorithms which then will be proved to be efficient according to definitions presented in the previous lecture. The importance sampling schemes that we shall study in this lecture belong to the class of state-independent changes-of-measure, and we will see that often, when they work, are unique within this class. Hopefully we will finish the lecture with counter-examples for which a direct interpretation of a state-independent conditional distributions based on large deviations do not lead to efficient algorithms. This will open up the way to our third lecture, which will involve state-dependent importance samplers.
- Tuesday, February 6, 2007
Topics on Rare-Event Simulation III
Jose H. Blanchet (Harvard University) In the third lecture we will continue our discussion on rare-event simulation algorithms for random walk problems with light-tailed increments. The uniqueness of logarithmically efficient iid importance samplers will be established for the tail of the sum in a large deviations regime. We will then talk about rare-event simulation problems for sample-path events and analyze some of the examples discussed in the first lecture in the context of finance, insurance and queueing. Some counter-examples will be shown to indicate that care is needed if we use large deviations to interpret the asymptotic description of the optimal change-of-measure. Then, we will introduce state-dependent importance sampling algorithms and discuss a series of connections to certain non-linear differential equations that appear in game theory and were introduced recently in work of Paul Dupuis and Hui Wang.
- Tuesday, February 13, 2007
Topics on Rare-Event Simulation IV
Jose H. Blanchet (Harvard University) We finished the third lecture with a brief discussion of sample path large deviations for light-tailed random walks. In this lecture, we will analyze the efficiency of importance sampling schemes for some sample path events (related to pricing of digital knock-in options and ruin problems). We then introduce state-dependent importance samplers and talk about Lyapunov-type inequalities that are useful to analyze their efficiency. These types of inequalities can be applied to problems with light or heavy-tailed features.
- Thursday, February 22, 2007, 11 am - noon
Tail Expansions for the Distribution of the Maxima of Random Walks with Negative Drift and Regularly Varying Increments
Chenhua Zhang (University of Giorgia) There is hardly a more basic stochastic model than a random walk, and for random walks with negative drift, a basic issue of study is the distribution of its global maximum. We consider the random walk generated by a distribution function with negative mean and regularly varying right tail. Under a mild smoothness condition we derive higher order asymptotic expansions for the tail distribution of the maxima of the random walk. The expansion is based on an expansion for the right Wiener-Hopf factor which we derive first. Computations of the expansions can be easily implemented with a computer algebra package such as Maple. An application to ruin probabilities is developed.
- Wednesday, February 28, 2007, 4pm , Room 149
Fractals and Multifractals: Old Themes and a Surprising New Construction
Benoit Mandelbrot (Yale University) A) Background
B) Yet another fractal dimension that can be measured experimentally. It can be negative and if so measures the degree of emptiness of a "latent set."
C) Non-random structures that become degenerate under randomization.
- Thursday, March 1, 2007, 10 am - noon, Room 135
Two applications of max-stable distributions: Random sketches and Heavy-tail exponent estimation
Stilian Stoev (University of Michigan) Max-stable distributions arise in the limit of (rescaled) maxima of independent and identically distributed random variables. They can be viewed as the analog of the Normal and stable laws, when the operation of summation in the Central Limit Theorem is replaced by the maximum. In this talk, we present two different applications of the max--stable laws.
We start by reviewing the definition of max-stable distributions, with emphasis on the heavy-tailed, Frechet max-stable laws. As a first application, we introduce the max-stable random sketches which provide efficient statistical summaries of extremely large streaming data. Such data are ubiquitous in modern data base, data mining, Internet traffic and other computer science applications. We demonstrate how one can approximate norms, distances and dominance norms of large data sets from much smaller max--stable random sketches.
The second application is to the classical problem of estimating the tail exponent of a heavy-tailed (power law) distribution. An estimator of the tail exponent is derived from the max--spectrum of the data. The max-spectrum reflects the scaling of heavy--tailed maxima and is not unlike the wavelet spectrum of a long--range dependent process. The proposed estimator is shown to be asymptotically normal in a semi-parametric setting and quite robust in practice. A new solution to the difficult problem of automatically choosing the ``scales'' is proposed from the perspective of the max--spectrum.
Based on joint works with Murad S. Taqqu, Marios Hadjieleftheriou and George Kollios.
- Tuesday, March 6, 2007
Stable convergence of generalized stochastic integrals, and applications to Bayesian survival analysis
Giovanni Peccati (Universite de Paris VI, France) We will discuss some recent results, concerning the weak and stable convergence of functionals of random measures, having the special form of generalized stochastic integrals. Our main results are based on a decoupling technique (known as the "principle of conditioning"), and are used to obtain CLTs for double integrals (and quadratic forms) associated with random Poisson measures. An application to Bayesian models of survival analysis will be also described. The talk is based on joint works with M.S. Taqqu and I. Pr�nster.
- Tuesday, March 20, 2007
Asymptotic behavior of distribution densities of the stock price and the implied volatility in the Hull-White model
Archil Gulisashvili (Ohio University) The Hull-White model is one of the standard stock price models with stochastic volatility. The stock price process in this model is the solution of the stochastic differential equation for Geometric Brownian motion driven by another Geometric Brownian motion. We give an explicit formula for the leading term in the asymptotic expansion of the distribution density of the stock price process at zero and at infinity. A similar problem is solved for the time average of the volatility process. We also study the behavior of the implied volatility in the Hull-White model for small and large values of the strike price. This is a joint work with E. M. Stein (Princeton University).
- Tuesday, March 27, 2007
Levy class L --- forgotten distributions?
Zbigniew J. Jurek (Wroclaw University, Poland) The usual central limit theorem provides the limit of normalized sums of independent and identically distributed (i.i.d.) random variables with finite second moments. Dropping assumptions on the second moments leads to stable distributions, A. Khintchine (1930's) asked to describe the class of limiting distributions arising from random variables, where only INDEPENDENCE is assumed.
A first result due to P. Levy (1935q) gave an answer in terms of infinitely divisible distributions. These limiting distributions are now called "selfdecomposbale" or "class L distributions".
In 1968 K.Urbanik, using Chouquet's Theorem on extreme points, found a complete description of the class L in terms of characteristic functions --- a description analogous to the famous Levy-Khintchine formula.
In 1983, Z. J. Jurek and W. Vervaat found that class L distributions coincide with distributions of some random integral. From that description Urbanik's formula from 1968 follows easily.
Recently class L distributins found applications in statistics, mathematical finance and statistical physics (Ising models). Furthermore, we now realize that many commonly used distributions like chi-square, t-Student, F-Fisher, hyperbolic, tempered stable and some functions of those distributions ALL BELONG TO THE LEVY CLASS L.
This talk will introduce these distributions.
For reference see:
Z. J. Jurek and J. David Mason,(1993): 'Operator-limit distributions in probability theory", J. Wiley, New York.
- Tuesday, April 17, 2007
How complete random permutations affect the dependence structure of stationary sequences with long-range dependence
Yingchun -Jasmine- Zhou (Boston University) A stationary time series is said to be long-range dependent (LRD) if its autocovariance function decays as a power of the lag, in such a way that the sum (over all lags) of the autocovariances diverges. The asymptotic rate of decay is determined by a parameter H, called the Hurst parameter. The time series is said to be short-range dependent (H=1/2) if the sum converges.
It is commonly believed that a random permutation of a sequence maintains the marginal distribution of each element but destroys the dependence, and in particular, that a random permutation of an LRD sequence creates a new sequence whose estimate of Hurst parameter H is close to 1/2. We provide here a theoretical basis for investigating these claims.
In reality, a complete random permutation does not destroy the covariances, but merely equalizes them. The common value of the equalized covariances depends on the length N of the original sequence and it decreases to 0 as N goes to infinity. Using the periodogram method, we explain why one is led to think, mistakenly, that the randomized sequence yields an ``estimated H close to 1/2''.
- Tuesday, April 24, 2007
Are Financial Data Stationary? Evidence from Temporal and Spatial Estimators.
Jeff Hamrick (Boston University) A strictly stationary stochastic process has time-invariant finite-dimensional distributions, which means that, in particular, it has time-invariant moments. Hypothesis tests regarding the stationarity of a diffusion that use the first moment are problematic because estimating the drift function is problematic.
We define two nonparametric estimators for the diffusion function (at some point in time and, therefore, some realized point in space). The first estimator uses data that are very close in time. The other estimator uses data that are very close in space, but not close in time. We state results regarding the asymptotic distribution of both estimators, and we also state results regarding the asymptotic independence of the two estimators.
Because of asymptotic independence, these two estimators can be combined in a special way to produce a new estimator that has smaller mean integrated square error than either the temporal or spatial estimator alone. We can also use these two estimators to construct a "visual hypothesis test" regarding the stationarity of various diffusions.
We simulate an Ornstein-Uhlenbeck process and another diffusion with a stationary distribution and find no evidence of non-stationarity from the spatial and temporal estimators. We also consider the temporal and spatial estimators when they are constructed for a simulated non-stationary diffusion, stock data, and real exchange rate data. Not surprisingly, if the financial data are diffusions, then it is unlikely that they are stationary.
Go to the top of the list for time and place.

{kind=link}
{kind=link}